

こんにちは、ログリーエンジニアの大久保です。普段は自然言語系学習エンジンの開発をやっています。
インターネットの広告配信システムは、学習システムによって時間が経てば基本的に最適化されますが、最適化にかかる時間は広告の数に比例して大きくなります。仮に、広告を数百数千で抱えていた場合、最適化にかかる時間が増えることによる収益の低下が大きな問題となります。そのような場合、似ている広告同士が適切にグループ化されていれば、まとめた分だけ最適化にかかる時間を圧縮できます。
例えば、既に収益性の高い配信方法がわかっている広告とこれから配信する広告のターゲットが似ている場合、既にわかっている収益性の高い配信方法を活用することで、短時間のうちに効率良く配信することが可能です。
ここでは広告の収益性を上げるグループ化手法の中から、オーディエンスの行動をもとに広告グルー プをつくる方法を紹介します。
なぜ行動ベースで広告グループをつくる必要があるのか
初めに、なぜオーディエンスの行動履歴から広告グループをつくる必要性があるのか、についてお話します。インターネット広告を男性向けや女性向け、健康意識が高い人向けや美容意識が高い人向けなど、グループをつくって配信する場合、広告をどのグループに入れるかだけでなく、そもそもどのようなグループをつくれば良いのかという問題と向き合う必要があります。
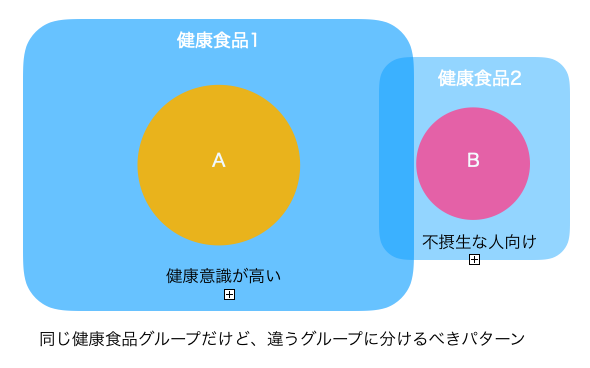
例えば、同じ健康食品であっても、不摂生をしている人向けの健康食品と普段から健康的な生活をしている人向けの健康食品では、不摂生をしているオーディエンスがジャンクフードやB級グルメの記事に興味を示しても、他方の普段健康的な生活をしているオーディエンスは興味を示さない、ということが予想されます。
このように同じ健康食品とカテゴライズされていても、行動ベースで見るとターゲットとなるオーディエンスの行動が大きく異なるものが存在します。このような性質の異なるオーディエンスの行動をターゲットのオーディエンス行動として学習してしまうと、意味不明なことになってしまいます。
そこでこのような場合、純粋に健康意識が高い人向けの広告グループと、不摂生している人向けの広告グループに分割するほうが合理的であることがわかります。
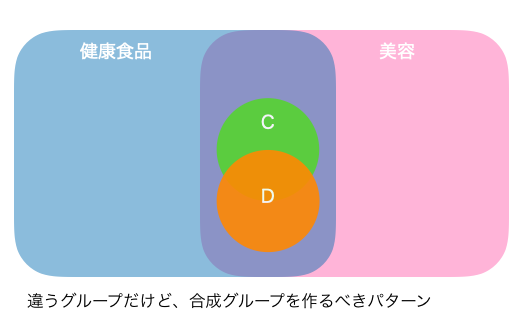
また上記とは逆の例で、現在は違うグループにカテゴライズされていても、新しい合成グループをつくるべき例があります。女性向けの健康食品商材Cのオーディエンス群と美容商材Dのオーディエンス群の行動履歴がよく似ていた場合、両者を別のグループにそれぞれ入れておくよりも、2つを組み合わせた新しい広告グループをつくるほうが良いことがわかります。
行動履歴をベースに広告グループをつくるメリット
このように、広告をオーディエンスの行動ベースで比較して、似ているものをグループにまとめると次のようなメリットを期待できます。
・人間が恣意的につくったグループよりも効率が良くなる
・素早く最適な配信方法に辿り着ける
・未知の広告に対しても、既存のオーディエンス群との行動比較によって、効果的な配信方法を短時間で見つけることが可能になる
これらがオーディエンスの行動ベースで広告配信グループをつくるべき理由となります。
具体的にグループ化する手法について
類似性でグループ化を行う場合、王道的な手法は似ているものを集めてボトムアップ的にグループをつくって行く手法ですが、この問題に対してボトムアップ的にアプローチすると、大きな問題にはまってしまいます。その理由と問題を回避する方法について説明します。
グループの類似性分布がイメージしやすいように、下記の2枚の画像を用意しました。この画像はオーディエンス群の行動類似度の強さを引力に変換し、3次元空間でどのように引き合うかをシミュレートした画像となっています。それぞれの点は広告オーディエンス群の行動を意味し、線は広告同士のつながりの強さを表しています。近くにあるものほど類似度が高く、遠くにあるものほど似ていないことを示しています(実際の計算は、n次元の超立体に対して行います)。

広告同士の類似度を表す2枚の図を見ると、中央付近の密度が高く、周辺はそれに比べて密度が低いことがわかると思います。このような分布に対してボトムアップでグループ化を行うと、重心近くに下記図のような巨大な分類グループができ上がってしまいます。
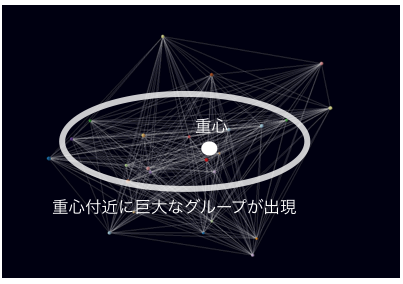
この重心近くのグループは分類的には特徴がないことを意味するため、ここに巨大な分類グループができてしまうと、分類できないものが増えて大きな問題となります。回避策としては、でき上がった判定不能グループの中で特徴の少ないもの同士を比較し、階層グループ化する方法もありますが、その方法は少ない特徴同士を学習するため良いやり方ではありません。
オススメはトップダウン的なアプローチ
この問題に対するオススメの解決策は、ベクトルを使ったトップダウン的なアプローチになります。アプローチのイメージは、問題をクラスタリングするのではなく、広告の成分分析に読み替えて問題解決をするイメージになります。
まず、下記図の各点を点ではなく重心からのベクトルと考えます。ベクトルの場合、ベクトルの合成によって各方向の一番外側のベクトルがあれば、内側のベクトルは表現できることがわかります。この性質を利用したグループ化は、各方向において一番外側のベクトルによって内側のベクトルをベクトルの合成として表現することにより、可能となります。
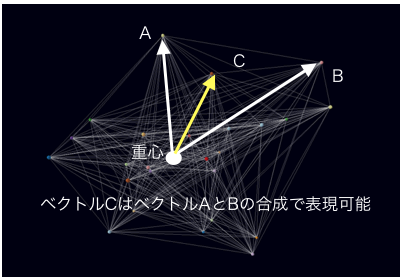
ここで1つ重要なことは、このような類似性を表したベクトルにおいて、方向は何らかの行動の特徴を表しているという点です。
つまり、健康志向の人の行動が他グループの行動と異なれば、その差は必ず何らかの方向のベクトルとして現れるということです。そのため、仮に健康志向を示す方向を特定できた場合、その方向において最も外側に飛び出ているベクトルがあれば、それは現在あるベクトルの中で、最も健康志向らしい人の行動を表しているベクトル、ということになります。このようなベクトルを、ここでは「特徴表現ベクトル」と呼びます。
どのように「特徴表現ベクトル」を見つけるか
この「特徴表現ベクトル」は、幾何学的手法で探すことができます。広告ごとにオーディエンスの行動類似度を距離とするn次元の超立体をつくり、その超立体をさまざまな角度から眺めた時に一番外側にある頂点が「特徴表現ベクトル」となります。 計算的には下記のような超立体の2次元写像を作り、その図形の内包点と頂点を求める形で「特徴表現ベクトル」を求めます。
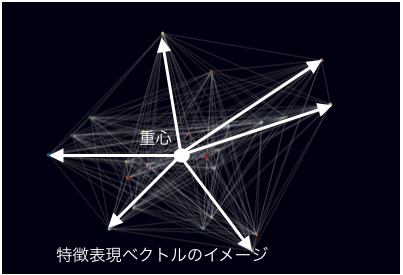
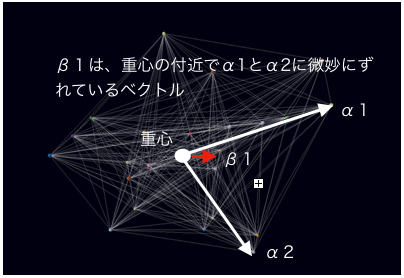
そして、この「特徴表現ベクトル」があれば、下図のβ1のような重心近くのベクトルであっても、重心からα1とα2方向に微妙にずれた合成ベクトルとして、効果的に表現できます。
少し抽象的な話でわかりにくいと思いますので、この話を日常生活の場合に当てはめてみましょう。
あるところに普通のネコやヒョウやトラは知っているけれど、山猫がどんな生き物かを知らない人がいたとします。この人に山猫がどんな生き物かを説明をする場合「山猫は、普通のネコが、少しヒョウやトラみたいになった生き物だよ」と説明すると、わかりやすいと思いませんか?
この話において、山猫は表現したいベクトル、普通のネコは重心、ヒョウやトラは「特徴表現ベクトル」に相当します。つまり、我々も日常で相手の知らない何かを表現する時に、お互いに知っているものの中から最も説明に適したものを選び、それを使って目的のものを表現しています。このアプローチでやろうとしていることも本質的には同じで、既知のベクトルの中で最も説明に適したものを選び、それを使って目的のベクトルを表現する、ということを行なっています。既知のベクトルの中で最も説明に適したものは、計算によって求めることが可能なのでその性質を利用する、という点がポイントです。
まとめ
以上の説明で、行動履歴をベースにしたグループ化が必要な理由、そしてどのようにグループをつくれば良いかの概要がわかったと思います。実際にこの手法を用いる場合、多次元超立体の頂点と内包点を確かめるアルゴリズムや、「特徴表現ベクトル」が、本当に特徴表現ベクトルかどうかを確認するアルゴリズムが重要になってきます。このあたりについては、また時間のあるときにお話できればと思います。