

どうもこんにちは。ログリー技術部の落合です。
普段は管理画面をいじったり、配信システムをいじったり、ログの集計基盤をいじったりといろいろやっています。
最近、今年2度目のぎっくり腰をやらかしまして、もっと真剣に運動するべきか悩み中です。
今回は、気になっているAmazon SageMakerで、独自に作成したDockerイメージを使ってモデルを訓練する方法を解説したいと思います。
また、今回の記事は既になんとなくSageMakerがどういうサービスか大体わかっている人向けの記事となっています。
SageMakerって何だっけ? という方や、ちょっとチュートリアル的なやつを動かしてみたい! という方は、下記ページなどを参考にしていただくと幸せになれるかもしれません。
AWS SageMakerは機械学習のモデル作成からホスティングまでクラウドで単純化してくれます
【初心者向け】Amazon SageMakerではじめる機械学習 #SageMaker
おさらい: Amazon SageMakerとは
SageMakerは、AWSの提供する機械学習のサービスです。
AWSの中の人曰く、「差別化を産まない重労働」を減らすことをコンセプトにしたプラットフォーム。データサイエンティストや機械学習エンジニアが、面倒なインフラ管理に時間をかけないで済むようにするために、さまざまなサービスが提供されています。
プラットフォームというだけあって、SageMakerにはいろいろな機能が存在しますが、例えば、下記のような機能がSageMakerには存在しています。
1. AWSの管理画面から数ステップでJupyter Notebookが起動したインスタンスを構築、利用
2. モデルを訓練する時など、コンピュータリソースが大量に必要になる時だけ、高性能なインスタンスを使用して訓練させる
3. SageMaker自身が組み込みの機械学習アルゴリズムを実装しており、有名なアルゴリズムなら容易に試せる
4. 訓練したモデルを利用した推論を行えるHTTPSのエンドポイントの構築
また、SageMakerの利用者は、これらの機能をすべて利用しなければならないというわけではなく、必要に応じて自分が使いたい機能だけを利用可能です。
広告配信エンジニアから見たSageMaker
広告配信システムは非常に短いレスポンスタイムを要求されるため、SageMakerが提供してくれるエンドポイントを直接本番の配信システムから呼び出すことは非現実的だと思います。
また、モデルが利用する訓練データの前処理についても、SageMakerが用意してくれるNotebookインスタンスを使って前処理するというよりは、あらかじめSparkなりHadoopなりを使って用意したデータを使用することが多いのではないでしょうか。
したがって、もし配信システムに組み込むとするとするならば、配信サーバで利用するモデルをオフラインで訓練するためのサービスとして利用することになるでしょう。
SageMakerの基本的な仕組みは、S3に訓練データを設置 → API経由で訓練用のJobを登録 → 訓練用Dockerコンテナが訓練データを自動で読み込んで訓練 → 学習結果(任意のフォーマットを使用可能)を所定のS3ディレクトリに出力
という流れになるため、広告配信システムでは、S3に出力された何らかの学習結果をキャッシュするなり、さらに加工するなりして使うイメージです。
SageMakerで独自のアルゴリズムを使ってモデルを訓練する
SageMakerは代表的な機械学習アルゴリズムをビルトインで用意しているのですが、それ以外のアルゴリズムを利用してモデルを訓練したい時は、自分でDockerイメージを作成し、ECRに登録してSageMakerの訓練用APIを経由してコンテナを起動する必要があります。
ところが、公式サイトをはじめ、ここら辺の情報がまとまっているサイトが少なく調査が大変だったことが、今回の記事を執筆するきっかけとなりました。
前置きが長くなってしまいましたが、これからSageMakerで独自アルゴリズムを使ってモデルを訓練し、S3に訓練結果を出力するまでの手順を解説したいと思います。
独自アルゴリズムでのモデル訓練には、大枠、次の工程に分けられます。
1.訓練用のデータと、モデルの出力先のディレクトリを所定のS3バケットに用意
2.訓練用のアルゴリズムを組み込んだDockerイメージを作成し、ECRに登録
3.SageMakerのJupyter Notebookインスタンスから訓練用APIを呼び出して訓練開始
訓練用データとモデルの出力先ディレクトリを所定のS3バケットに用意
今回は仮想の広告配信結果のデータを生成し、生成したデータに対して広告のクリックされやすさを予測するモデルをpymc3を使ってつくってみようと思います。
テストデータとして、下記のルールで50,000行のテストデータを生成しました。
・ ベースとなるクリック率(CTR)は15%で(普通はこんなに高くないですが、現実的なCTRでデータをつくるとクリックされたデータの数が極端に少なくなるので……)、広告や広告枠の種類によってCTRは変動する。
・ id1~10を持つ10種類の広告を用意する。それぞれの広告はidが高くなればなるほどCTRが低くなる。
・ id1~10を持つ10種類の広告枠を用意する。それぞれの広告枠はidが高くなればなるほどCTRが高くなる。
テストデータを用意するために使ったスクリプトと、実際に作成したテストデータはこちらに置いてありますので参考にしてください。
作成したテストデータは、S3のバケットにアップロードしてください。
アップロードするバケットは基本任意なのですが、SageMakerの初回起動時に作成するAmazonSageMaker-ExecutionRoleというIAM Roleには’sagemaker’という文字列が含まれるバケットしか読み取り・書き込み権限がなさそうなので注意してください。
今回は s3://logly-sagemaker-test/sagemaker_sample/ の中にtrain_data.csvをアップロードしました。
訓練用のアルゴリズムを組み込んだDockerイメージを作成し、ECRに登録
次に、訓練用のDockerイメージを作成します。今回はカスタムイメージの中でベイズ推定を行って、推定結果をS3に出力する形にしたいと思います。
1からイメージをつくるのは面倒なので、 jupyter/scipy-notebook のイメージを少しカスタマイズしてpymc3を利用できるようにしました。
使用するDockerfileは、下記のような感じです。
FROM jupyter/scipy-notebook:621b96ed75cb
ENV MKL_THREADING_LAYER GNU
RUN conda install -y -c conda-forge
'awscli=1.15.62'
'mkl=2018.0.3'
'mkl-service=1.1.2'
'pymc3=3.5'
'pyarrow=0.9.0'
ADD ./train /usr/local/bin/train
ADD ./train.py /home/jovyan/train.py
# デフォルトのユーザーjovyanは /opt 以下への実行・書き込み権限がないので、rootユーザーで実行するように修正
USER root
ポイントはADDで追加しているファイルです。
SageMakerでカスタムイメージを使用してモデルの訓練を行う際、SageMakerは指定されたDockerイメージを
docker run image名 train
というコマンドで呼び出します。なので、推論処理のエントリーポイントとなるtrainの処理を /usr/local/bin 配下に設置しました。
trainの処理の内容は、次のようにtrain.pyを呼び出しているだけですね。
#! /bin/sh
python /home/jovyan/train.py
本体は train.pyの部分で、こんな感じのコードにしています。
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import pymc3 as pm
from scipy import stats
import json
# Jobの登録時に設定したhyperparameterの読み取り
with open('/opt/ml/input/config/hyperparameters.json') as f:
hyperparameters = json.load(f)
sample_size = int(hyperparameters['sample_size'])
# 広告アイテムと広告枠の種類がCTRに与える影響を推定
csv_file = f"/opt/ml/input/data/sagemaker_sample/train_data.csv"
train_data = pd.read_csv(csv_file)
ad_id_data = pd.Categorical(train_data['ad_id'].values).codes
adspot_id_data = pd.Categorical(train_data['adspot_id'].values).codes
is_clicked_data = train_data['is_clicked'].values
with pm.Model() as logistic_model:
alpha = pm.Uniform('alpha', lower=-4, upper=1)
ad_coefs = pm.Normal('ad_coefs', mu=0, sd=1, shape=len(set(train_data['ad_id'].values)))
adspot_coefs = pm.Normal('adspot_coefs', mu=0, sd=1, shape=len(set(train_data['adspot_id'].values)))
p = pm.Deterministic('p', pm.math.sigmoid(alpha + ad_coefs[ad_id_data] + adspot_coefs[adspot_id_data]))
yl = pm.Bernoulli('yl', p=p, observed=is_clicked_data)
trace = pm.sample(sample_size, chains=2)
summary = pm.summary(trace, varnames={'alpha', 'ad_coefs', 'adspot_coefs'})
summary.to_csv("/opt/ml/model/result.csv")
ポイントは3つあります。
1. /opt/ml/input/config/hyperparameters.json は訓練用のJobをAPIから登録するときに引数として渡したハイパーパラメータがjsonで記載されています。今回はMCMCのサンプル数をハイパーパラメータとして訓練用Job登録時に渡すことで、サンプリング回数を調整できるようにしています。なんのことかまだイメージがつきにくいと思うので、ここでは読み飛ばしていただいても大丈夫です。
2. SageMakerでは、コンテナ内の /opt/ml/input/data/{channel_name} ディレクトリの下に、訓練用のテストデータなどの入力データを配置できます。{channel_name}と、設置したいファイルを保存してあるS3のパスの組み合わせをJob登録時のAPIの引数の1つとしてセットするイメージです。今回は’sagemaker_sample’ というchannel_nameと、test_data.csvを保存してあるS3のパスの組み合わせを引数として渡すつもりです。
3. 訓練結果の成果物は、何らかのフォーマットに変換して /opt/ml/model ディレクトリの中に保存すると、SageMakerが自動でS3に保存してくれます。保存先のS3のパスも後述のJob登録APIの引数として設定します。
SageMakerのJupyter Notebookインスタンスから訓練用APIを呼び出して訓練開始
S3とECRの準備ができたら、最後にSageMakerのノートブックインスタンスからtrainというAPIでSageMakerに訓練用のJobを登録します。
訓練用のjobに渡す引数も結構必須項目が多かったり、型や決まりごとが多いので、下記のコードを参考に呼び出してみてください。
session.train(
image="your-aws-id.dkr.ecr.ap-northeast-1.amazonaws.com/intentad/sagemaker:sagemaker_sample",
# 訓練に使うデータの渡し方
# 'File' を使うとS3経由になる
input_mode='File',
# チャンネルオブジェクトのリスト
# channel_nameと訓練データを保存したS3のパスの組み合わせを入力する
input_config=[{
"ChannelName": 'sagemaker_sample',
**sagemaker.session.s3_input('s3://logly-sagemaker-test/sagemaker_sample/').config
}],
#
role='arn:aws:iam::your-aws-id:role/service-role/AmazonSageMaker-ExecutionRole-20180606T170033', # required
job_name='sagemaker-sample-20180812-6', # required 同じjob_nameは2度と使えないので、命名は慎重に!
output_config={
'S3OutputPath': 's3://logly-sagemaker-test/output/' # required 訓練結果の出力先のS3パスを入力
},
resource_config={
'InstanceType': 'ml.m5.2xlarge', # required モデルの訓練時に立ち上げるインスタンスタイプ
'InstanceCount': 1, # required モデルの訓練時に立ち上げるインスタンスの個数。分散処理しないなら1でOKのはず
'VolumeSizeInGB': 32 # required
},
# 先ほどDockerイメージをつくる時に出てきたハイパーパラメータ。ここで渡したパラメータが'/opt/ml/input/config/hyperparameters.json'に書き込まれる
hyperparameters={
'sample_size': '10000' # hyperparametersのvalueは文字列型である必要があるので注意。訓練用のスクリプトで適宜型変換等が必要
}, # required
tags=[{
'Key': 'Name',
'Value': 'sagemaker-sample'
}], # required
stop_condition={ # required
'MaxRuntimeInSeconds': 60 * 60 * 2 # 2時間で終わらなかったら強制終了
}
)
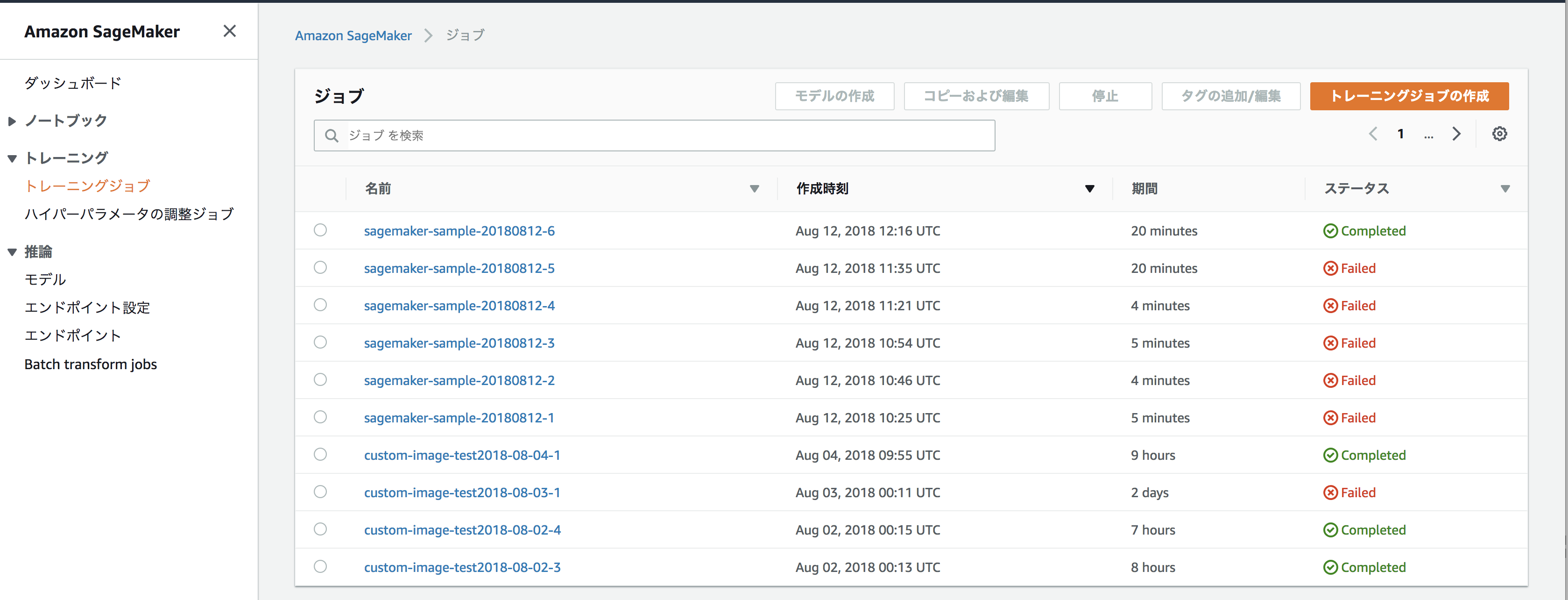
登録されたJobの実行結果は、SageMakerコンソールのトレーニングジョブという項目から確認することができます。
Statusの項目にCompletedと表示されていれば無事成功です! このトレーニングジョブの画面から、各Jobの詳細な実行結果や
Clowdwatchに出力されたログの確認などもできるので、デバッグしたい場合はそちらを参照してみてください。
いかがでしたでしょうか。以上でSageMakerで独自のDockerイメージを使ってモデルの訓練を行い、訓練結果をS3に保存するまでの流れを解説はおしまいです。
これだけだと、まだまだ本番運用するためには考えないといけない項目が多そうですが、少しでもみなさんのお役に立てれば幸いです。
We’re hiring!
ログリーでは「テクノロジーで人々の生活を豊かに」したいエンジニアを募集しています。